Overview
Autonomous agents and LLM-based systems don’t crash—they fail quietly. They call the wrong function, drift off task, or return unsafe outputs without triggering any exceptions. Traditional tracing and observability tooling doesn’t capture the problem.
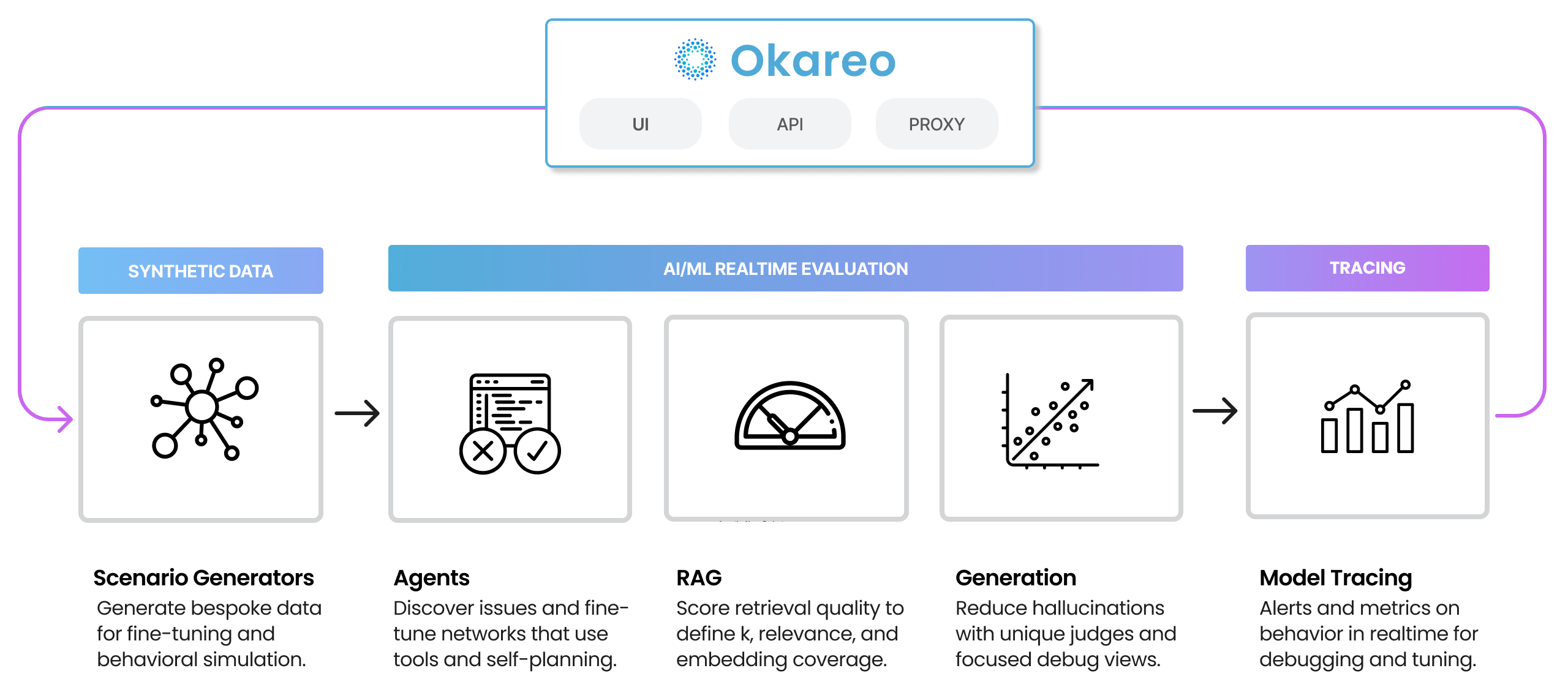
Okareo provides behavior-level visibility into what’s really happening inside LLM workflows and agentic applications. You can track decisions step-by-step, catch issues like scope violations or failed tool calls in real time, and evaluate and monitor how your agents plan, make decisions, and complete tasks. Whether you're working on function-calling agents, multi-turn dialogs, or retrieval-augmented pipelines, Okareo gives you tools to track behavior, surface patterns, and measure outcomes. With real-time detection and scenario-based evaluations, you can verify that what you’re building will hold up in production—across edge cases, workflows, and user roles.
Move beyond code traces — ship LLM behavior with confidence.

Real-Time Error Tracking
Agents and LLMs fail silently — your code runs fine, but your agent misfires. You don’t need another tracing tool — we track LLM behavior. Catch failures as they happen— scope violations, wrong tools, hallucinations, broken flows. Real-time detection maps where errors start, how they spread, and when they break trust.
Real-Time Error Tracking helps you detect:
- Unauthorized model output that flows past traditional observability
- Broken agent decisions that tracing won't find
- LLM workflows going off the rails, that erode user trust before you notice
Explore Real-Time Error Tracking →
Agentic Evaluation
Test your agents’ planning, memory, and decision-making, step-by-step. LLM agents don’t just generate text — they plan, call functions, and adapt. But when they go off-script, traditional evals can’t explain why. Okareo lets you simulate complex agent flows, test how they plan and remember, and catch decision-making flaws before users do.
Agentic Evaluation helps diagnose:
- Agents using the wrong tools or failing to recover from function call errors
- Agents forgetting key details from earlier turns, breaking task flow
- Conflicting actions that cause the agents to stall
- Tasks failing when agents act on incomplete or missing data from prior steps
Explore Function Calling →
Explore Multi-Turn Simulation →
Explore Multi-Agent →
RAG Evaluations
Validate intent detection, retrieval, and generation end-to-end. RAG systems break at any step — misclassified intent, poor retrieval, or hallucinated answers. Okareo tests each stage of your RAG pipeline with real metrics, so you can trust the full flow from query to answer.
RAG Evaluations help prevent:
- Queries being misrouted due to incorrect intent classification
- Poor document retrieval leading to bad LLM answers
- No measure or visibility of retrieval quality - recall and precision unknown
- Hallucinated answers caused by missing source content
Explore Classification →
Explore Retrieval Overview →
Explore Retrieval Metrics →
Explore Model Output Checks →
Synthetic Data & Scenario Copilot
Generate test scenarios before real users break things. Real-world coverage is impossible with hand-crafted prompts. Okareo’s Scenario Copilot creates rich, diverse, edge-case scenarios—before failure hits production. Expand your test set with realistic data, fast, and power your simulations with synthetic inputs that expose hidden flaws. Use real examples of production failures to expand safety nets and catch similar issues early.
Synthetic Data & Scenario Copilot helps address:
- Hand-written tests missing real-world edge cases
- New features ship with no coverage or examples
- Lack of edge case and stress testing leaves systems unproven under pressure
- Generating test data manually is slow and incomplete